5 Amazing Tricks To Get Probably the Most Out Of Your Deepseek
페이지 정보

본문
 5 The mannequin code was below MIT license, with DeepSeek license for the mannequin itself. Beyond self-rewarding, we are additionally dedicated to uncovering different general and scalable rewarding methods to persistently advance the mannequin capabilities on the whole eventualities. • We will discover extra comprehensive and multi-dimensional model evaluation strategies to forestall the tendency in direction of optimizing a fixed set of benchmarks throughout research, which may create a misleading impression of the model capabilities and affect our foundational evaluation. In K. Inui, J. Jiang, V. Ng, and X. Wan, editors, Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 5883-5889, Hong Kong, China, Nov. 2019. Association for Computational Linguistics. In Proceedings of the nineteenth ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, PPoPP ’14, web page 119-130, New York, NY, USA, 2014. Association for Computing Machinery. Kan, editors, Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601-1611, Vancouver, Canada, July 2017. Association for Computational Linguistics. Loshchilov and Hutter (2017) I. Loshchilov and F. Hutter. Joshi et al. (2017) M. Joshi, E. Choi, D. Weld, and L. Zettlemoyer.
5 The mannequin code was below MIT license, with DeepSeek license for the mannequin itself. Beyond self-rewarding, we are additionally dedicated to uncovering different general and scalable rewarding methods to persistently advance the mannequin capabilities on the whole eventualities. • We will discover extra comprehensive and multi-dimensional model evaluation strategies to forestall the tendency in direction of optimizing a fixed set of benchmarks throughout research, which may create a misleading impression of the model capabilities and affect our foundational evaluation. In K. Inui, J. Jiang, V. Ng, and X. Wan, editors, Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 5883-5889, Hong Kong, China, Nov. 2019. Association for Computational Linguistics. In Proceedings of the nineteenth ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, PPoPP ’14, web page 119-130, New York, NY, USA, 2014. Association for Computing Machinery. Kan, editors, Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601-1611, Vancouver, Canada, July 2017. Association for Computational Linguistics. Loshchilov and Hutter (2017) I. Loshchilov and F. Hutter. Joshi et al. (2017) M. Joshi, E. Choi, D. Weld, and L. Zettlemoyer.
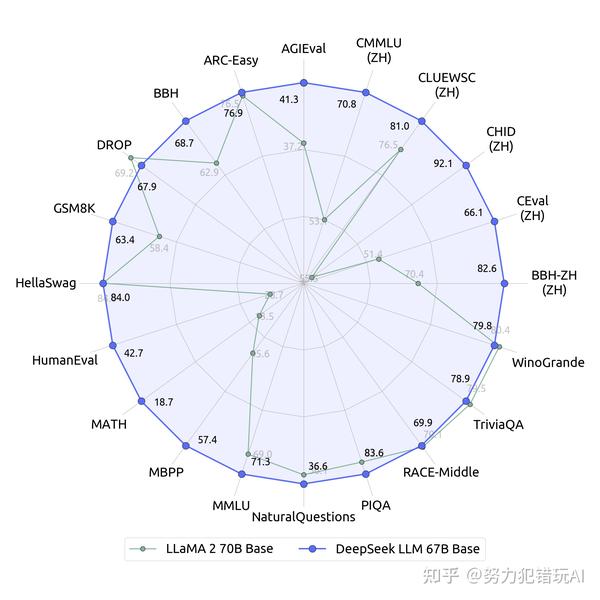 Secondly, although our deployment strategy for DeepSeek-V3 has achieved an end-to-end technology velocity of more than two times that of DeepSeek-V2, there still remains potential for further enhancement. For extra evaluation particulars, please verify our paper. As well as, on GPQA-Diamond, a PhD-degree evaluation testbed, DeepSeek-V3 achieves exceptional results, rating just behind Claude 3.5 Sonnet and outperforming all other opponents by a considerable margin. Table 6 presents the analysis outcomes, showcasing that DeepSeek-V3 stands as the best-performing open-source mannequin. Notably, it surpasses DeepSeek-V2.5-0905 by a significant margin of 20%, highlighting substantial enhancements in tackling easy tasks and showcasing the effectiveness of its developments. As well as to standard benchmarks, we also consider our fashions on open-ended technology tasks utilizing LLMs as judges, with the outcomes proven in Table 7. Specifically, we adhere to the original configurations of AlpacaEval 2.Zero (Dubois et al., 2024) and Arena-Hard (Li et al., 2024a), which leverage GPT-4-Turbo-1106 as judges for pairwise comparisons. DeepSeek-V3-Base and DeepSeek-V3 (a chat mannequin) use basically the same architecture as V2 with the addition of multi-token prediction, which (optionally) decodes extra tokens quicker but much less accurately. So for my coding setup, I use VScode and I found the Continue extension of this particular extension talks on to ollama without much setting up it additionally takes settings in your prompts and has support for multiple models depending on which activity you are doing chat or code completion.
Secondly, although our deployment strategy for DeepSeek-V3 has achieved an end-to-end technology velocity of more than two times that of DeepSeek-V2, there still remains potential for further enhancement. For extra evaluation particulars, please verify our paper. As well as, on GPQA-Diamond, a PhD-degree evaluation testbed, DeepSeek-V3 achieves exceptional results, rating just behind Claude 3.5 Sonnet and outperforming all other opponents by a considerable margin. Table 6 presents the analysis outcomes, showcasing that DeepSeek-V3 stands as the best-performing open-source mannequin. Notably, it surpasses DeepSeek-V2.5-0905 by a significant margin of 20%, highlighting substantial enhancements in tackling easy tasks and showcasing the effectiveness of its developments. As well as to standard benchmarks, we also consider our fashions on open-ended technology tasks utilizing LLMs as judges, with the outcomes proven in Table 7. Specifically, we adhere to the original configurations of AlpacaEval 2.Zero (Dubois et al., 2024) and Arena-Hard (Li et al., 2024a), which leverage GPT-4-Turbo-1106 as judges for pairwise comparisons. DeepSeek-V3-Base and DeepSeek-V3 (a chat mannequin) use basically the same architecture as V2 with the addition of multi-token prediction, which (optionally) decodes extra tokens quicker but much less accurately. So for my coding setup, I use VScode and I found the Continue extension of this particular extension talks on to ollama without much setting up it additionally takes settings in your prompts and has support for multiple models depending on which activity you are doing chat or code completion.
On math benchmarks, DeepSeek-V3 demonstrates exceptional performance, significantly surpassing baselines and setting a new state-of-the-art for non-o1-like fashions. This demonstrates its outstanding proficiency in writing duties and handling simple question-answering scenarios. This characteristic broadens its applications throughout fields akin to actual-time weather reporting, translation companies, and computational duties like writing algorithms or code snippets. MMLU is a extensively recognized benchmark designed to assess the efficiency of large language fashions, across various information domains and tasks. Better & quicker giant language models through multi-token prediction. Program synthesis with massive language fashions. The Pile: An 800GB dataset of diverse textual content for language modeling. Additionally, we'll try to break via the architectural limitations of Transformer, thereby pushing the boundaries of its modeling capabilities. Expert recognition and reward: The brand new model has acquired important acclaim from trade professionals and AI observers for its efficiency and capabilities. The router is a mechanism that decides which professional (or specialists) should handle a selected piece of knowledge or process. The second mannequin receives the generated steps and the schema definition, combining the data for SQL generation. This modern strategy not only broadens the variety of training materials but in addition tackles privateness issues by minimizing the reliance on real-world knowledge, which can often include sensitive data.
This method not solely aligns the model extra closely with human preferences but in addition enhances efficiency on benchmarks, particularly in eventualities where out there SFT data are limited. Remember to set RoPE scaling to 4 for right output, extra dialogue could possibly be discovered on this PR. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Gshard: Scaling giant fashions with conditional computation and automatic sharding. DeepSeek-AI (2024b) DeepSeek-AI. Deepseek LLM: scaling open-source language fashions with longtermism. Scaling FP8 coaching to trillion-token llms. Mixed precision coaching. In Int. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and units a multi-token prediction training goal for stronger efficiency. Training verifiers to unravel math word issues. The rule-based reward was computed for math issues with a remaining reply (put in a box), and for programming problems by unit checks. Rewardbench: Evaluating reward fashions for language modeling. Fewer truncations enhance language modeling. Because all consumer data is stored in China, the biggest concern is the potential for a knowledge leak to the Chinese government. Caching is ineffective for this case, since each information learn is random, and isn't reused.
If you have any queries with regards to where by and how to use شات DeepSeek, you can speak to us at our own web site.
- 이전글Custom dissertation ghostwriters for hire online 25.02.08
- 다음글Cabane à Chauves-Souris : Un Refuge par Nos Amies Nocturnes 25.02.08
댓글목록
등록된 댓글이 없습니다.